Apache Kafka - czym jest i z czego się składa
Kafka od Środka: Architektura systemu
Apache Kafka to dzisiaj jedno z tych narzędzi, o których słyszy się wszędzie tam, gdzie mowa o przetwarzaniu danych w czasie rzeczywistym. Nieważne, czy chodzi o analizę kliknięć na stronie, logi z setek serwerów, czy śledzenie zamówień w e-commerce – Kafka często gra tam pierwsze skrzypce. Nic dziwnego, że pojawia się w czołówce technologii poszukiwanych na rynku pracy.
Ale co tak naprawdę kryje się pod maską Kafki? Jak to działa, że potrafi obsłużyć ogromne ilości danych, być odporna na awarie i jednocześnie elastyczna? Kluczem jest jej sprytna architektura. Przyjrzyjmy się jej bliżej, rozbierając Kafkę na części pierwsze.
Serce Systemu: Klaster i Brokerzy
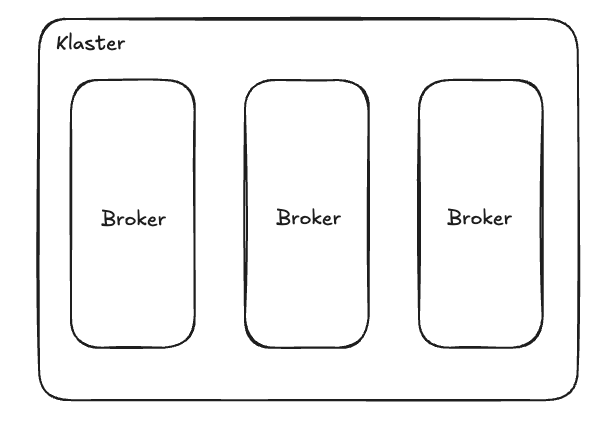
Podstawą każdej instalacji Kafki jest klaster – czyli po prostu grupa serwerów, które ze sobą współpracują. Każdy taki serwer w klastrze to broker. Broker to pojedyncza, działająca instancja Kafki. Jego zadaniem jest przyjmowanie wiadomości, zapisywanie ich na dysku i udostępnianie tym, którzy chcą je odczytać.
Pomyśl o klastrze jak o zespole pracowników (brokerów), którzy dzielą się pracą, aby obsłużyć duży ruch. Jeśli jeden pracownik zachoruje (broker ulegnie awarii), reszta zespołu może przejąć jego obowiązki. A jeśli pracy jest za dużo, można zatrudnić nowych (dodać kolejne brokery do klastra). To właśnie daje Kafce skalowalność i odporność na awarie.
W każdym klastrze jest też jeden "szef" – Kontroler Klastra. To jeden z brokerów, wybrany automatycznie, który pilnuje porządku: zarządza podziałem zadań (który broker zajmuje się którymi danymi), zauważa, gdy któryś broker ma problemy i reaguje na zmiany w klastrze. W nowszych wersjach Kafki (korzystających z KRaft, o czym za chwilę) rolę kontrolera może pełnić kilka dedykowanych maszyn lub nawet być ona rozproszona między brokerami, co jeszcze bardziej zwiększa niezawodność.
Jak Kafka Organizuje Dane: Tematy i Partycje
Wyobraź sobie, że Kafka to ogromna poczta. Aby wiadomości się nie pogubiły, potrzebne są kategorie. W Kafce takimi kategoriami są tematy (topics).
Temat to po prostu nazwany strumień danych – na przykład zamowienia, logi_aplikacji, aktywnosc_uzytkownikow.
To logiczna nazwa, taki kanał lub szyna danych dla konkretnego rodzaju informacji. Zatem topic służy do identyfikowania strumienia danych, ale sam w sobie nie jest ich fizycznym nośnikiem.
Kafka dzieli każdy temat na mniejsze, niezależne części zwane partycjami (partitions), które odpowiadają folderom na dysku.
- Równoległość: Różne partycje tego samego tematu mogą być obsługiwane przez różne brokery (serwery) w klastrze. Dzięki temu można przetwarzać dane z jednego tematu jednocześnie na wielu maszynach.
- Kolejność Gwarantowana (ale z gwiazdką): Kafka obiecuje, że wiadomości wewnątrz jednej partycji będą zawsze ułożone w dokładnie takiej kolejności, w jakiej do niej trafiły. Każda wiadomość w partycji dostaje swój unikalny numer porządkowy – offset. Offsety rosną sekwencyjnie (0, 1, 2, 3...). Ważne: Kafka nie gwarantuje kolejności między różnymi partycjami tego samego tematu.
- Niezmienny Log: Wiadomości raz zapisane do partycji nie mogą być zmienione. Nowe wiadomości po prostu dopisywane są na koniec. To jak dziennik zdarzeń, który tylko rośnie.
- Przechowywanie: Dane w partycjach są trzymane na dyskach brokerów przez określony czas (np. 7 dni) lub do momentu, aż log partycji osiągnie zadany rozmiar. Potem stare dane są usuwane.
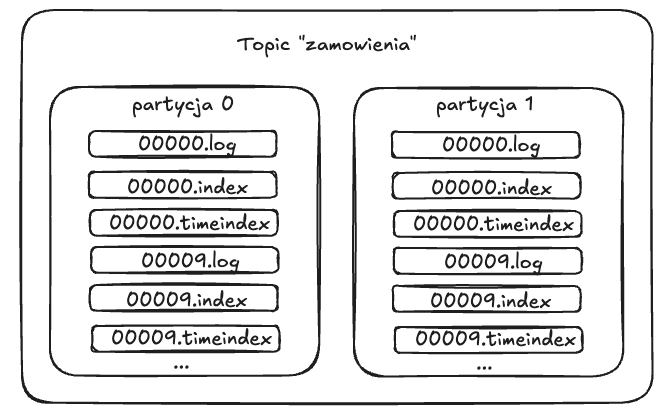
Na dysku, gdy wyświetlimy zawartość konkretnej partycji, od razu widać sposób, w jaki Kafka organizuje dane. Poniższe zdjęcie przedstawia strukturę partycji nr 0 z topicu my-topic.

Kolejne pliki z rozszerzeniem .log są segmentami przechowującymi napływające wiadomości. Nazwa pliku segmentu to pierwszy offset rekordów przechowywanych w tym
segmencie, więc 0000000000.log oznacza, że pierwsza wiadomość ma offset 0, a plik 0000000109.log (gdyby istniał) zaczyna się od offsetu 109.
Partycja składa się z wielu segmentów; ostatni z nich jest aktywny (tylko do niego broker dopisuje nowe wiadomości), a po przekroczeniu limitu rozmiaru lub czasu retencji
segment zostaje zamknięty i tworzony jest nowy. Do każdego segmentu Kafka utrzymuje dwa indeksy w pamięci (a następnie na dysku): indeks offsetowy w pliku .index,
mapujący logiczny offset na pozycję bajtową w segmencie, oraz indeks czasowy w pliku .timeindex, mapujący znacznik czasu na odpowiadający mu offset.
Indeks offsetowy jest rzadki – zawiera wpisy co określoną liczbę bajtów (domyślnie ok. 4096, ustawiane parametrem index.interval.bytes) – dzięki czemu każdy wpis zajmuje tylko 8 bajtów (4 B relatywny offset, 4 B pozycja). Indeks czasowy umożliwia szybkie „przewijanie” danych według czasu, co wykorzystuje się m.in. przy odczycie od zadanego timestampu i przy polityce retencji opartej na czasie. Oba indeksy, będąc memory‑mapped, pozwalają brokerowi w czasie O(1) odnaleźć rekordy bez skanowania całego pliku segmentu, a jednocześnie zachowują minimalny narzut przestrzeni dyskowej i pamięci.
Liderzy i Kopie Zapasowe: Odporność na Awarie w Praktyce
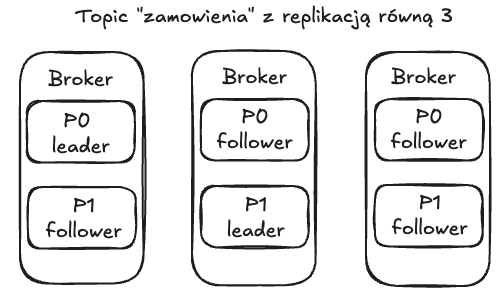
Aby dane były bezpieczne nawet jeśli jakiś serwer (broker) padnie, Kafka stosuje replikację. Dla każdej partycji można ustawić, ile jej kopii ma istnieć w klastrze (to tzw. współczynnik replikacji, np. 3).
- Lider (Leader): Zawsze jedna kopia partycji jest wyznaczona jako "główna" – to lider. Tylko lider obsługuje zapisy od producentów i odczyty od konsumentów dla tej konkretnej partycji.
- Obserwatorzy (Followers): Pozostałe kopie to obserwatorzy (lub repliki). Ich zadanie jest proste: muszą na bieżąco kopiować wszystko, co lider zapisuje. Są jak lustrzane odbicia lidera.
- Synchronizacja (ISR - In-Sync Replicas): Kafka pilnuje, którzy obserwatorzy "nadążają" za liderem. Ci, którzy są aktualni, tworzą grupę ISR (replik w synchronizacji). To ważne, bo tylko replika z grupy ISR może zostać nowym liderem, jeśli obecny lider ulegnie awarii. Dzięki temu mamy pewność, że nie stracimy danych, które zostały już potwierdzone jako zapisane.
Kto Wysyła, Kto Odbiera: Producenci i Konsumenci
Mamy już infrastrukturę (klaster, brokerzy) i sposób organizacji danych (tematy, partycje). Ale kto z tego korzysta?
-
Producenci (Producers): To aplikacje, które wysyłają (publikują) dane do Kafki. Na przykład serwis obsługujący koszyk w sklepie internetowym może być producentem wysyłającym wiadomości do tematu
nowe_zamowienia. Producent sam decyduje, do której partycji danego tematu trafi wiadomość:- Losowo (Round-robin): Jeśli wiadomość nie ma specjalnego "klucza", producent może wysyłać kolejne wiadomości do różnych partycji po kolei, żeby równo rozłożyć obciążenie.
- Według Klucza: Jeśli wiadomość ma klucz (np. ID użytkownika, ID zamówienia), producent użyje tego klucza, aby zawsze kierować wiadomości z tym samym kluczem do tej samej partycji. To super ważne, jeśli zależy nam na kolejności zdarzeń dotyczących tego samego obiektu (np. wszystkie aktualizacje dla zamówienia nr 123 muszą być przetwarzane po kolei).
- Potwierdzenia (
acks): Producent może też wybrać, jak bardzo chce być pewien, że wiadomość została zapisana. Może nie czekać na żadne potwierdzenie (szybko, ale ryzyko utraty), czekać tylko na potwierdzenie od lidera (dobry kompromis), albo czekać na potwierdzenie od lidera i wszystkich zsynchronizowanych replik (najbezpieczniej, ale wolniej).
-
Konsumenci (Consumers): To aplikacje, które odczytują (subskrybują) dane z tematów Kafki. Na przykład system do wysyłania powiadomień e-mail może być konsumentem tematu
nowe_zamowienia.- Pobieranie Danych (Pull Model): Konsumenci sami regularnie pytają brokerów: "Czy są jakieś nowe wiadomości dla mnie w temacie X?". Nie czekają biernie, aż dane zostaną do nich "wepchnięte".
- Śledzenie Postępu (Offsety): Każdy konsument musi pamiętać, do którego miejsca (offsetu) w każdej partycji już doczytał. Tę informację (ostatni przetworzony offset) zapisuje z powrotem w Kafce (w specjalnym temacie
__consumer_offsets). Dzięki temu, jeśli konsument się zrestartuje, wie dokładnie, od którego miejsca ma wznowić czytanie. - Grupy Konsumentów (Consumer Groups): Konsumenci mogą działać w grupach.
- Podział Pracy: Jeśli kilka instancji tej samej aplikacji (np. kilka serwerów wysyłających e-maile) należy do tej samej grupy konsumentów (mają to samo
group.id), Kafka automatycznie podzieli między nich partycje subskrybowanego tematu. Każda partycja będzie obsługiwana przez tylko jednego konsumenta z danej grupy w danym momencie. - Skalowanie: Chcesz przetwarzać dane szybciej? Po prostu uruchom więcej instancji konsumenta w tej samej grupie (do liczby partycji). Kafka sama rozdzieli pracę (ten proces nazywa się rebalansem).
- Odporność: Jeśli jeden konsument z grupy padnie, Kafka zauważy to i przydzieli jego partycje pozostałym aktywnym członkom grupy.
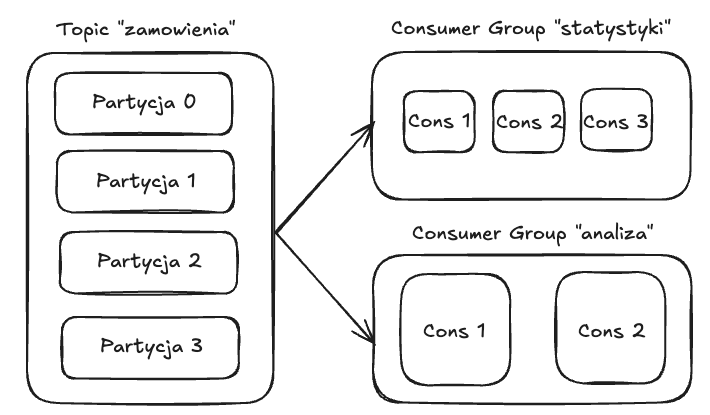
- Niezależne Strumienie: A co jeśli dwie różne aplikacje chcą czytać te same dane z tematu
zamowienia? Wystarczy, że będą należeć do różnych grup konsumentów. Wtedy każda grupa dostanie swoją własną, pełną kopię wszystkich wiadomości z tematu i będzie niezależnie śledzić swój postęp (offsety). Jedna grupa nie "podbiera" wiadomości drugiej. To genialne połączenie modelu kolejki (wiadomość dla jednego w grupie) i modelu publikacja/subskrypcja (każda grupa dostaje wszystko).
- Podział Pracy: Jeśli kilka instancji tej samej aplikacji (np. kilka serwerów wysyłających e-maile) należy do tej samej grupy konsumentów (mają to samo
Pod Powierzchnią: Segmenty i Indeksy
Wiemy już, że partycje to logiczne logi. Ale jak to wygląda fizycznie na dysku brokera? Kafka nie trzyma całej, potencjalnie gigantycznej partycji w jednym pliku. Zamiast tego, dzieli log każdej partycji na mniejsze kawałki – segmenty.
- Pliki Logów: Każdy segment to po prostu plik (
.log) o określonym maksymalnym rozmiarze (np. 1GB) lub obejmujący określony czas. Gdy aktywny segment się zapełni, Kafka go zamyka i tworzy nowy. - Łatwe Zarządzanie: Taki podział ułatwia życie. Kiedy trzeba usunąć stare dane (zgodnie z polityką retencji), Kafka może po prostu skasować całe stare pliki segmentów. To znacznie szybsze niż usuwanie pojedynczych wiadomości.
- Szybki Dostęp (Indeksy): Żeby szybko znaleźć wiadomość o konkretnym offsecie lub z konkretnego momentu w czasie, Kafka obok plików
.logtworzy pliki indeksów (.index,.timeindex). Działają one jak spis treści, pozwalając Kafce błyskawicznie skoczyć do odpowiedniego miejsca w pliku segmentu bez potrzeby czytania go od początku.
Mózg Operacji: ZooKeeper vs KRaft
Żeby cały ten złożony system działał sprawnie, brokerzy muszą się jakoś koordynować. Kto jest liderem której partycji? Którzy brokerzy są aktywni? Jakie są konfiguracje tematów?
- ZooKeeper (Stara Szkoła): Przez lata Kafka polegała na zewnętrznym systemie zwanym Apache ZooKeeper do przechowywania tych wszystkich metadanych i zarządzania klastrem (np. wyborem kontrolera). ZooKeeper jest sprawdzony, ale oznacza konieczność zarządzania osobnym systemem i mógł stanowić wąskie gardło przy bardzo dużych klastrach.
- KRaft (Nowe Porządki): W nowszych wersjach Kafka może działać bez ZooKeepera! Zamiast tego używa własnego, wbudowanego mechanizmu opartego na protokole konsensusu Raft (stąd nazwa KRaft - Kafka Raft). Metadane są przechowywane w specjalnym wewnętrznym temacie Kafki, a za ich zarządzanie odpowiada grupa wybranych węzłów (kontrolerów) używających Rafta. To upraszcza architekturę, zwiększa skalowalność (zwłaszcza liczbę partycji, jaką klaster może obsłużyć) i przyspiesza powrót do zdrowia po awarii. KRaft to obecnie zalecany sposób działania dla nowych wdrożeń.
Jak Płynie Wiadomość: Ścieżka od Producenta do Konsumenta
Zobaczmy to wszystko w akcji na przykładzie jednej wiadomości:
- Nadawca (Producent): Twoja aplikacja (np. sklep online) chce wysłać informację o nowym zamówieniu do tematu
zamowienia. Decyduje, do której partycji wysłać (np. na podstawie ID klienta, żeby jego zamówienia były w jednej partycji). - Znajdź Lidera: Klient producenta pyta Kafkę: "Kto jest liderem dla partycji X tematu
zamowienia?" i wysyła wiadomość bezpośrednio do tego brokera. - Zapis u Lidera: Broker-lider odbiera wiadomość, nadaje jej kolejny offset i zapisuje ją na końcu aktywnego segmentu na swoim dysku.
- Kopiowanie (Replikacja): Lider wysyła wiadomość do swoich obserwatorów (followers) dla tej partycji.
- Potwierdzenie: Obserwatorzy zapisują wiadomość i potwierdzają to liderowi. Gdy wystarczająca liczba replik z grupy ISR potwierdzi (zależnie od ustawienia
acksproducenta), lider wysyła ostateczne potwierdzenie do producenta: "OK, wiadomość bezpiecznie zapisana!". - Odbiorca (Konsument): Aplikacja należąca do grupy konsumentów (np. system fakturowania subskrybujący
zamowienia) pyta lidera partycji, którą ma przypisaną: "Czy masz dla mnie jakieś nowe wiadomości od offsetu Y?". - Dostarczenie: Lider odczytuje wiadomości z dysku (używając indeksów, jeśli trzeba) i wysyła je do konsumenta.
- Przetwarzanie: Konsument odbiera wiadomości, przetwarza je (np. generuje fakturę).
- Zaznaczenie Postępu (Commit): Po przetworzeniu, konsument informuje Kafkę: "Przeczytałem i przetworzyłem wiadomości do offsetu Z". Kafka zapisuje ten offset dla tej grupy konsumentów i tej partycji. Następnym razem konsument dostanie wiadomości od Z+1. Ważne: odczytanie wiadomości nie usuwa jej z Kafki!